
2026-03-05
186
原创
Learning Domain-Driven Design总结
Learning Domain-Driven Design总结
Domain领域
业务领域(Business Domain): 公司的主要经营活动业务, 也是公司能提供给客户的价值.
子领域(Subdomain): 为了获得业务领域的目标, 公司所从事的商业活动, 所有的子领域构成业务领域.
子领域(Subdomain)一般分为三种类型:
- 核心子领域(Core Subdomain): 最能体现公司价值和竞争力的业务活动. 通常具有复杂性, 竞争优势性, 易变性.
- 通用子领域(Generic Subdomain): 公司所从事业务领域中的通用解决方案, 比如技术框架, 网店平台等.
- 支撑子领域(Supporting Subdomain): 公司所从事业务活动时需要提供的支持性领域, 较核心子领域简单.
这些子领域之间可以相互转换. 当通用子领域或支撑子领域有了相应的商业机会时可以转为核心子领域; 当核心子领域和支撑子领域可以通过商品化购买技术时则变成了通用子领域; 当核心子领域简化到不是业务核心时或者通用子领域能够减少聚合代价时, 此时则变成了支撑子领域.
通用语言Ubiquitous Language
通过向领域专家学习业务知识形成通用语言(Ubiquitous Language). 通用语言必须是业务相关的语言而不是技术方面的, 必须消除术语的歧义和不精确的表述; 如果有相同的术语代表不同的事物, 需要不同的词语进行区分, 不建议使用相同的后缀加形容词前缀进行区分.
通用语言是需要随着业务领域的深入逐渐进化, 是一个持续不断过程.
边界上下文Bounded Context
将通用语言根据精确的上下文来划分为多种小语言, 相同的事物在不同的上下文中的功能不同. 通过不同的上下文将业务领域模型化, 不同的上下文形成不同的模型, 不同的模型解决业务的不同方面.
通用语言只有在边界上下文中才是通用的一致的, 语言描述模型要解决的业务问题的方面. 边界上下文的大小需要根据特定的业务问题领域来决定, 在设计的初期设置较大的边界, 随着业务知识的理解深入再划分为更能解决业务问题的上下文.
边界上下文和子领域的不同:
- 子领域是根据业务需求领域进行划分的, 而边界上下文是根据解决业务问题的方面来划分的.
- 子领域是被发现的, 而边界上下文是被设计出来的, 是设计策略决定.
一个边界上下文和它相关的通用语言只能被一个团队实现和维护, 边界上下文可以各自独立于其他上下文改变, 但它们必须在一起工作形成系统.
边界上下文的协作交互方式有:
- 合作伙伴(Partnership): 两个团队双向协调合作, 应用这种协作需要两个团队建立良好的合作关系, 高效的沟通和频繁的同步.
- 共享内核(Shared Kernel): 两个团队通过分享一个限制的功能重叠的模型, 该模型属于所有参与的边界上下文. 适用于重复的代价高于聚合的代价, 即适用于变化频繁的模型.
- 顺从模式(Conformist): 消费者团队顺从于服务提供者的模型. 通常服务提供者提供的协议是符合工业标准的, 良好设计的模型.
- 反腐败层(Anticorruption Layer): 消费者团队转换服务提供者的模型成适合消费者需求的模型. 当消费者团队的边界上下文包含核心子领域时, 当服务提供者的模型不适合消费者的需求时, 当服务提供者的模型变更频繁时, 可以使用该方式.
- 开放主机服务(Open-Host Service): 服务提供者实现一种公用协议供消费者使用, 是反腐败层的反向, 屏蔽消费者模型经常改变带来的调整.
- 分离方式(Separate Ways): 如果重复特定的功能模型的代价比协作和整合的代价小时, 可以使用该方式.
业务逻辑的实现
简单业务逻辑的实现
事务脚本(Transaction Script): 通过编写SQL脚本实现业务功能. 适用于简单的业务逻辑, 比如ETL(Extract-Transform-Load)提取转换加载操作, 适用于支撑子领域, 绝不能用于核心子领域.
活动记录(Active Record): 通过封装了数据库操作的对象(ORM)来执行业务操作, 支持有继承或关联的数据库对象操作, 支持CRUD, 适用于支撑子领域.
复杂业务逻辑的实现
使用领域模型范式实现复杂的业务逻辑, 其中包括三种主要的构建块:
值对象(Value Object): 只需要对象的值不需要特定的ID的业务领域对象, 当对象改变时创建新的值对象, 值对象是不可变的. 值对象可封装操作其值的方法, 可包含其他的值对象.
聚合(Aggregate): 包含多个有体系的实体且分享同一个事务边界的对象, 所有包含在聚合对象里数据一直处于强一致的状态. 聚合对象的状态, 其包含的对象都只能通过其提供的公共接口来修改. 聚合对象的数据字段对于外部组件来说是只读的, 保证所有的业务逻辑封装在聚合对象中.
聚合对象可以通过发布领域事件和外部的实体进行交互, 领域事件是指在聚合对象生命周期里重要的业务事件. 其他实体或组件可通过订阅这些事件来触发业务逻辑的执行.
领域服务(Domain Service): 无状态的对象用来执行不属于任何领域模型聚合对象或值对象的业务逻辑. 比如需要操作多个聚合对象完成复杂业务.
事件源领域模型Event-Sourced Domain Model
事件源领域模型Event-Sourced Domain Model应用于领域模型中聚合对象的时间维度处理.
在事件源领域模型中, 所有关于聚合对象的状态改变都会表达为一系列领域事件, 与传统的状态改变就修改记录的方式不同, 产生的领域事件用于影射聚合对象的当前状态.
这个模型范式适用于需要对系统的数据进行深入研究的情况, 比如分析和研究, 或者依据法律要求的审计日志.
可靠发布事件的模式
收件箱(OutBox)模式: 首先使用同一个事务更新聚合(Aggregate)和领域事件(Domain Event)到数据库中, 然后一个消息中继器(Message Relay)从该数据库中拉取已经提交的领域事件, 消息中继器把领域事件发布到消息总线(Message Bus)上, 如果发布成功标记为已发送或者彻底删除事件.
收件箱模式可以确保消息的传递至少成功一次, 可能会造成重复发布的情况.
Saga模式: 专门用来处理跨组件且最终一致的长事务业务. 当事件发布失败时, saga负责提起相关的补偿事务保障系统的状态的一致性.
流程管理器(Process Manager)模式: 使用一个处理业务流程的中心化单位去维护状态, 根据状态决定下一步. 流程管理器模式可以用于处理比saga模式更复杂的业务流程.
架构模式Architecture Pattern
架构模式(Architecture Pattern)不仅给代码库提供了组织原则和清晰的边界, 如业务逻辑如何关联系统的输入输出和其他的基础设施组件, 而且还影响了组件之间交互方式.
主流的架构模式有下面三种:
层次架构(Layered Architecture): 层次架构是从逻辑划分的层次, 从上到下通常有表现层(Presentation Layer), 业务逻辑层(Business Logic Layer), 数据访问层(Date Access Layer), 只能上层调用下层的功能. 有的层次架构变体还有服务层(Service Layer), 介于表现层和业务逻辑层之间.
端口适配器(Ports & Adapters): 该架构模式的核心是解耦系统的业务逻辑和它所依赖的基础设施组件. 业务逻辑层定义端口, 让基础设施层实现; 基础设施层实现适配器, 端口接口的具体实现用于不同的技术协作.
命令查询职责分离(Command-Query Responsibility Segregation CQRS): 与端口适配器架构模式相同, 核心同样是解耦系统的业务逻辑和它所依赖的基础设施组件. 但该架构模式在系统数据管理方式上有所不同, 该模式支持多种持久化模型来表示数据. 适用于在线事务处理和在线分析处理需要不同的系统数据呈现方式时, 或者需要不同种类的持久化模型来支持不同的功能时(比如使用关系型数据库进行业务操作, 使用列数据库进行分析报告, 使用查询引擎来增强搜索能力).
CQRS需要两个职责模型: 命令执行模型和读模型.
命令执行模型(Command Execution Model): 用于执行修改系统状态的业务操作, 实现业务逻辑, 验证规则等. 该模型应该是强一致的
读模型(Read Model): 可以定义多个读模型去满足用户或其他系统的要求. 读模型是预缓存的映射, 可存在于数据库, 文件, 内存中. 合理的CQRS的实现允许抹除所有映射的数据从头开始生成, 允许通过添加额外的映射来扩展系统.
CQRS的映射Projection生成可通过同步或异步的方式, 当遇到分布式环境时由于保障不了顺序和不重复, 推荐大部分通过同步生成, 部分使用异步生成.
做出设计决策
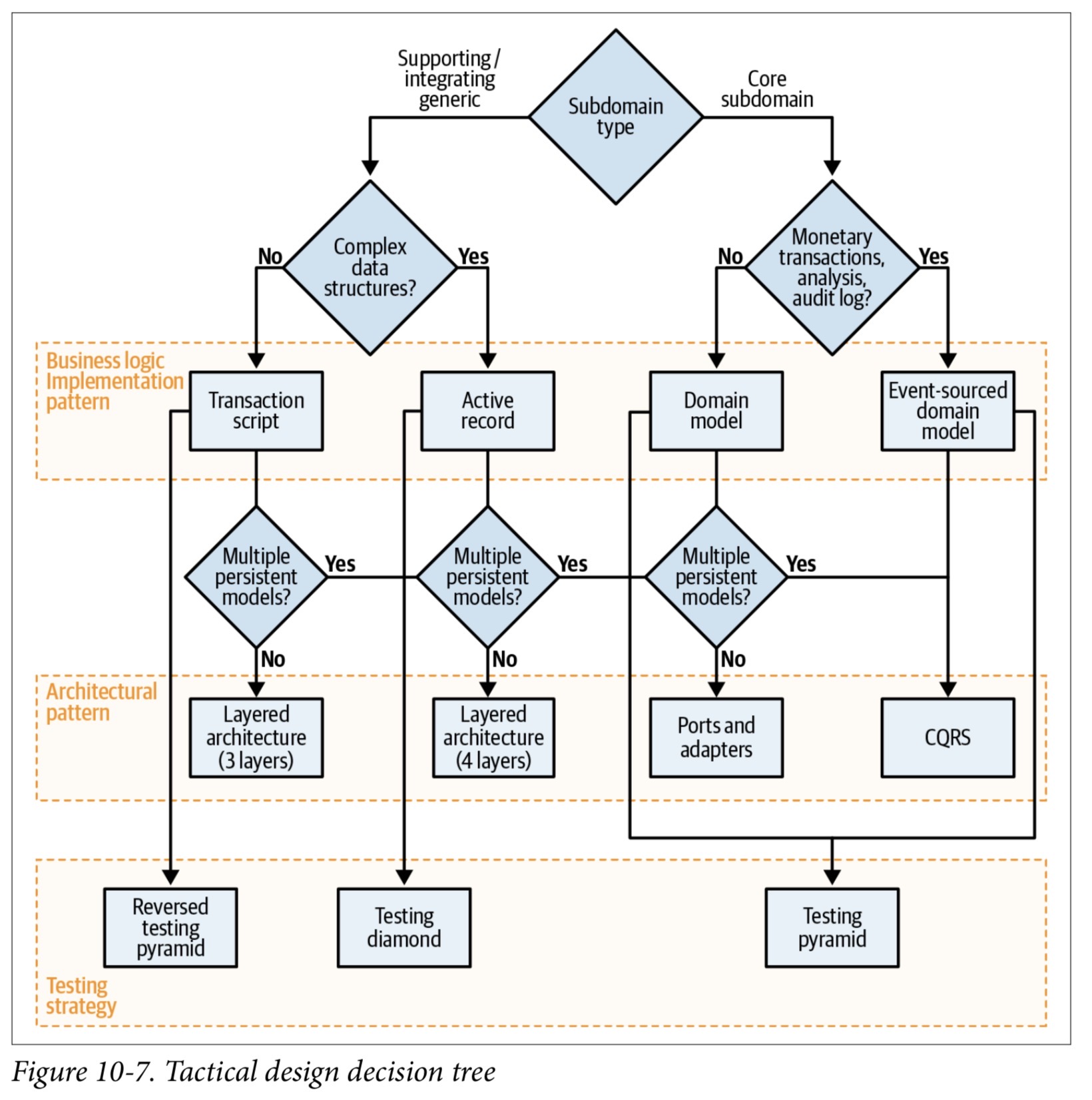
根据图中给出的设计决策树做出相应的模式.
实践建议
唯一不变的是变化
随着业务领域的进化, 不同的子领域之间会相互转换, 边界上下文的交互方式也会发生变化, 组件之间的沟通模式也会发生变化, 当需要注意的是:
- 当一个子领域的功能扩大时, 试着转换为更好颗粒度的子领域能够使你做出更好的设计决策.
- 不允许一个边界成为一个全能的, 包含所有业务的上下文. 确保边界上下文的模型是专注于解决特定问题的.
- 确保聚合对象的边界尽可能的小, 用强一致的数据去提取业务逻辑到聚合对象中.
事件风暴
可以通过事件风暴(EventStorming)来模型化业务, 共享领域知识并建立统一语言, 探索新的业务需求, 恢复原有模型的知识, 探索新的方式去优化现有的流程, 和新的团队成员共享领域知识.
微服务
微服务架构和DDD领域驱动设计深度关联, 微服务和边界上下文几乎是对等的. 但需要注意所有的微服务都是边界上下文, 但边界上下文不必一定是微服务. 微服务定义了最小的有效边界, 而边界上下文保护了其包含的所有模型一致性且代表最宽的有效边界. 定义边界如果比边界上下文更宽, 那么这会变成一团大泥球, 而如果比微服务边界更小, 这会造成分布式大泥球.
事件驱动
事件驱动架构中的事件(Event)类型通常有三种:
- 事件通知(Event Notification): 通知某些重要的事情发生了, 但是需要事件消费者自己去查询事件生产者来获得进一步的准确信息.
- 携带事件的状态转换(Event-carried State Transfer): 基于消息数据的重复机制, 每个事件都包含能够缓存到消费者本地并进行相应处理的快照状态数据.
- 领域事件(Domain Event): 描述生产者业务领域事件的消息.
领域事件和事件通知的不同:
- 领域事件包含所有描述事件的信息, 消费者无需再有进一步的动作获取.
- 领域事件的目的是用来模型化和描述业务领域, 而事件通知的目的只是为了减轻组件之间的聚合交互.
领域事件和携带事件的状态转换的不同:
- 携带事件的状态转换提供充足的信息以至可以保持本地生产者数据缓存, 而单个领域事件不应暴露如此丰富的信息. 即使是特定领域事件中过包含的数据也不足以用于缓存聚合状态, 因为消费者未订阅的其他领域事件可能会影响同样的字段.
- 领域事件中的数据不是用来描述聚合对象的状态的, 而是描述聚合对象生命周期内发生的业务事件.
当组件可以处理保证最终一致性的数据时, 可以使用携带事件的状态转换(Event-carried State Transfer)方式来传递消息.
当消费者需要读取最新写入的生产者状态时, 使用事件通知(Event Notification)方式, 收到通知后通过查询生产者当前最新状态.
使用事件驱动架构时, 意味着整个系统都基于成功的事件传递, 因此需要确保事件传递的一致性. 比如使用收件箱(Outbox)模式来确保发布消息可靠; 当发布消息时, 需要确保订阅者能够区分重复消息且能够重新排序已混乱的消息; 当跨边界上下文交互流程需要补偿事务时, 可以利用Saga模式或流程处理器(Process Manager)模式.
分析数据模型
主流的分析数据模型有星状模式和雪花模式. 星状模式是多对一的事实和其维度关系, 每个维度记录用于多个事实, 而一个事实的外键指向单独的味维度记录. 而雪花模式更进一步, 有多个不同层级的维度. 这两个模型都用于数据分析以提供业务性能优化, 数据洞察, 商业情报等.
而这些分析数据管理的平台架构有数据仓库(Data Warehouse)和数据湖(Data Lake). 数据仓库则是通过ETL(提取转换加载)流程把数据转换为用于分析的数据. 而数据湖则是直接采集业务系统的数据, 再通过ETL流程把数据转换为用于分析的数据. 这两种架构都擅自闯入业务系统的边界, 依赖业务系统实现的细节, 通常造成业务和分析两个系统团队因为改变而发生的冲突; 而数据分析家和数据工程师不属于同一个组织团队, 这样导致他们经常缺乏业务团队深入的领域知识.
而使用数据网格(Data Meth)架构可解决上述问题. 数据网格架构是为分析数据的DDD领域驱动设计, 同样定义模型和边界. 数据网格架构基于四个核心原则:
- 根据领域解耦数据: 根据边界上下文划分相应的分析模型和数据.
- 数据即是产品: 通过定义了好的端口或公共的API来获取分析数据
- 数据自治: 数据基础设施团队通过定义数据蓝图, 统一访问模式和访问控制, 多种形态存储, 来抽象化数据产品的构造, 执行, 维护等.
- 建立生态: 联合治理小组制定规则确保生态系统健康可互操作, 这些规则必须用于所有数据产品及其接口.
上述的核心原则和DDD领域驱动设计具有一致合理的原因, 一些DDD领域驱动设计的模式可用于支撑实现数据网格:
- 统一语言和领域知识是设计分析模型的基础.
- 在不同于业务模型的模型中暴露边界上下文的数据是开放主机(Open-Host)模式, 此时分析模型相当于是一个额外的发布语言.
- CQRS模式让为相同的数据生成多个模型更简单, 该模式可用于将业务模型转换为分析模型, 同时因为该模式容易从头创建模型, 同样容易同时生成和服务多个版本的分析模型.
- 数据网格架构同样聚合多种不同的边界上下文模型以实现分析实例, 业务模型的边界上下文的交互方式同样适用于分析模型.
程序员内功
架构技术
